Conventional, Uni-Temporal and
Bi-Temporal Tables
Conventional tables contain data describing what things are currently like. But to provide comparable access to data describing what things used to be like, and to what they may be like in the future, we believe it is necessary to combine data about the past, the present and the future in the same tables. Tables which do this, which contain data about what the objects they represent used to be like and also data about what they may be like later on, together with data about what those objects are like now, are versioned tables.
Another important thing about data is that, from time to time, we occasionally get it wrong. We might record the wrong data about a particular customer's status, indicating, for example, that a VIP customer is really a deadbeat. If we do, then as soon as we find out about the mistake, we will hasten to fix it by updating the customer's record with the correct data. But that doesn't just correct the mistake. It also covers it up. Auditors are often able to reconstruct erroneous data from backups and logfiles. But for the ordinary query author, no trace remains in the database that the mistake ever occurred, let alone what the mistake was, or when it happened, or for how long it went undetected.
Fortunately, we can do better than that. Instead of overwriting the mistake, we can keep both the original customer record and its corrected copy in the same table, along with information about when and for how long the original was thought to be correct, and when we finally realized it wasn't and then did something about it. Moreover, while continuing to provide undisturbed, directly queryable, immediate access to the data that we currently believe is correct, we can also provide that same level of access to data that we once believed was correct but now realize is not correct. This is important for re-creating reports, or query results, showing the data as it was at the time those reports or queries were originally run.
There is no generally accepted term for this kind of table. We will call it an assertion table. Assertion tables, as we will see, are essential for recreating reports and queries, at a later time, when the objective is to retrieve the data as it was originally entered, warts and all. Assertion tables are the second of the two kinds of uni-temporal tables. The same data management methods which lower the cost and increase the value of versioned data also lower the cost and increase the value of asserted data.
Version tables and assertion tables are both uni-temporal tables. The difference between them is what their time periods represent, and how they are managed. If the begin date of the time period indicates when the row representing an object was physical created, and the end date indicates when either an update or a delete transaction was processed for the same object, then the time period is a physical time period and the table is an assertion table. In effect, it is a logfile, differing from conventional logfiles in that updates are stored as after-images, not as the transactions themselves. On the other hand, if the begin date of the time period indicates when the object represented by the row entered into the state described by that row, and the end date indicates when that object is no longer in that state, then the time period is a logical time period and the table is a version table.
There are also tables which combine versions and assertions, and combine them in the sense that every row in these tables is both a version and an assertion. These tables contain data about what we currently believe the objects they represent were/are/will be like, data about what we once believed but no longer believe those objects were/are/will be like, and also data about what we may in the future come to believe those objects were/are/will be like. Tables like these, tables whose rows contain data about both the past, the present and the future of things, and also about the past, the present and the future of our beliefs about those things, are bi-temporal tables.
Figure 1 shows a conventional, a uni-temporal and a bi-temporal table. Here and elsewhere, our convention is to underline primary key column headings.
We also show time period columns as containing both a begin and an end point in time, and we refer to these points in time as "dates". They can actually be any representation of a point in time, and would more typically be timestamps. We use the special date "12/31/9999" when we do not know if or when a time period will end.
Of course, if these time periods are represented by single columns, then those columns have a time period datatype, and do not consist of a pair of dates. Commercial DBMSs are beginning to support time period datatypes. But because that support is neither ubiquitous nor standardized, we use a pair of columns in our implementations, one to mark the beginning of the time period, and the other to mark the end of the time period. More precisely, following the standard convention, we set the begin date of a time period to the first point in time in the period, and the end date of the time period to the first point in time after the end of the time period.
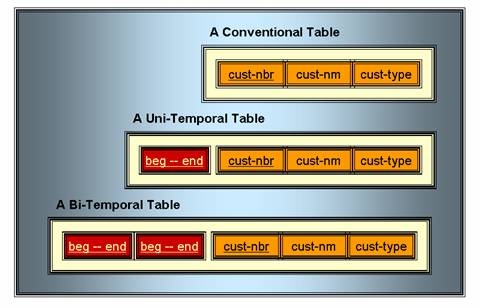
Figure 1. A Conventional, Uni-Temporal and Bi-Temporal Table.
The first table illustrated in Figure 1 is a very simple conventional table. Each customer is represented by one row in the table. If the customer's name or type changes, the row is updated to reflect the change. Also, if we discover an error in the data for a particular customer, we update the row to correct the error.
The second table illustrated in Figure 1 is a uni-temporal table. Whether it is a version table or an assertion table is, as we explained above, a matter of how the time periods are interpreted. But in either case, the same customer may be represented by any number of rows in the table.
The third table illustrated in Figure 1 is a bi-temporal table. To demonstrate the value of a bi-temporal table – what it can represent that a conventional or a uni-temporal table cannot represent – we will use an example. In Figure 2, we see a sample row in the bi-temporal form of our customer table. It was physically inserted on May 1st, a month before it was due to go into effect.
# |
E-Begin |
E-End |
A-Begin |
A-End |
Cust |
Name |
Type |
1 |
06/01/2008 |
12/31/9999 |
05/01/2008 |
12/31/9999 |
C123 |
Jones |
Silver |
Figure 2. An Insert.
In Figure 3, we see an update applied to this customer's data. The result of the update is that the first row is logically deleted or, as we will say, withdrawn into past assertion time. It is a record of what we once said was true about Jones. But beginning on September 15th, we no longer make that claim, and so this row is logically no longer part of the database. In place of that row, beginning on September 15th, we make two claims. The first is that Jones was a Silver customer from June 1st to September 15th. The second is that, starting on September 15th and continuing on until further notice, Jones is a Gold customer.
# |
E-Begin |
E-End |
A-Begin |
A-End |
Cust |
Name |
Type |
1 |
06/01/2008 |
12/31/9999 |
05/01/2008 |
09/15/2008 |
C123 |
Jones |
Silver |
2 |
06/01/2008 |
09/15/2008 |
09/15/2008 |
12/31/9999 |
C123 |
Jones |
Silver |
3 |
09/15/2008 |
12/31/9999 |
09/15/2008 |
12/31/9999 |
C123 |
Jones |
Gold |
Figure 3. An Update.
In Figure 4, we see a correction made to this customer's data. A week after processing the update, we discovered that the transaction was incorrect, and that Jones should actually have been changed to a Platinum customer.
The result of the update is that the first row is logically deleted or, as we will say, withdrawn into past assertion time. It is a record of what we once said was true about Jones. But beginning on September 15th, we no longer make that claim, and so this row is logically no longer part of the database. In place of that row, beginning on September 15th, we make two claims. The first is that Jones was a Silver customer from June 1st to September 15th. The second is that, starting on September 15th and continuing on until further notice, Jones is a Platinum customer. We make the correction by withdrawing row #3 and creating row #4.
# |
E-Begin |
E-End |
A-Begin |
A-End |
Cust |
Name |
Type |
1 |
06/01/2008 |
12/31/9999 |
05/01/2008 |
09/15/2008 |
C123 |
Jones |
Silver |
2 |
06/01/2008 |
09/15/2008 |
09/15/2008 |
12/31/9999 |
C123 |
Jones |
Silver |
3 |
09/15/2008 |
12/31/9999 |
09/15/2008 |
09/22/2008 |
C123 |
Jones |
Gold |
4 |
09/15/2008 |
12/31/9999 |
09/22/2008 |
12/31/9999 |
C123 |
Jones |
Platinum |
Figure 4. A Correction.
This correction has been made without losing any information, specifically without losing the information that, from September 15th to September 22nd, a report based on this table would show Jones as having a customer type of Gold, starting on September 15th. Yet the correction has been recorded correctly. It states that Jones has a customer type of Platinum, starting on September 15th.
If the business requests a report showing what the database currently says each customer's type is, the report will show that Jones is currently a Platinum customer. And if the business requests a report showing, for example, what the database said, or would have said, on September 18th, that each customer's type is, that report will show that Jones is currently a Gold customer.
Our final transaction is a delete, and is shown in Figure 5. It shows a deletion entered on November 5th, to take effect right after December 31st.
# |
E-Begin |
E-End |
A-Begin |
A-End |
Cust |
Name |
Type |
1 |
06/01/2008 |
12/31/9999 |
05/01/2008 |
09/15/2008 |
C123 |
Jones |
Silver |
2 |
06/01/2008 |
09/15/2008 |
09/15/2008 |
12/31/9999 |
C123 |
Jones |
Silver |
3 |
09/15/2008 |
12/31/9999 |
09/15/2008 |
09/22/2008 |
C123 |
Jones |
Gold |
5 |
09/15/2008 |
12/31/9999 |
09/22/2008 |
11/05/2008 |
C123 |
Jones |
Platinum |
6 |
09/15/2008 |
12/31/2008 |
11/05/2008 |
12/31/9999 |
C123 |
Jones |
Platinum |
Figure 5. A Delete.
Bi-temporal tables contain the data necessary to answer questions of the form "What did the database say, at point in time X, that certain objects were like at point in time Y?" Neither conventional nor uni-temporal tables can answer these questions.
Although this example is accurate in all respects, managing bi-temporal data as rows in bi-temporal tables is, in real-world databases, much more complex than this example indicates. For example, we have not shown any retroactive transactions, ones that create rows that describe the state an object entered prior to when the transaction was applied. However, row #5 does show the result of a proactive transaction, one that creates a row prior to when the object will enter the state described by that row.
Also, we have not illustrated any situations in which referential integrity is involved. Clearly, referential integrity between bi-temporal tables will be more difficult to manage than referential integrity between conventional tables, or between uni-temporal tables. For example, when a customer is represented by several rows in a temporal customer table, and there is an invoice table which is referentially dependent on that customer table, which of the rows for that customer do that customer's invoices point to?
Closely related to the issue of implementing referential integrity for temporal tables is the issue of creating and managing primary and foreign keys for temporal tables. For example, how should time periods be represented in primary keys? How can we prevent the time periods for two rows for the same customer from overlapping?
One more way in which bi-temporal data management is more complex than shown here is that corrections seldom line up, one for one, with rows already in the table. Suppose, for example, that the correction we needed to make is that Jones was briefly a Platinum customer from November 21st to December 2nd, but was indeed a Gold customer from September 15th to November 21st, and reverted to being a Gold customer on December 3rd.
Because of these complexities, we have completely encapsulated the procedural logic involved in managing bi-temporal data within our software, the Asserted Versioning Framework. Users or application programs issue Instead Of queries. Each of these queries is captured by the Asserted Versioning Framework, which validates the transaction and then issues the one or more physical transactions required to correctly update the database.
|
|
|||
|
|
|||
|
|